Part one of this article is located here.
In a previous post we discussed the benefit of a reusable ingestion architecture and demonstrated one way this might look in Matillion. What we call “Always On Tables.” Today we are revisiting that pattern to make a few improvements which will further reduce the development effort when adding new tables. Be sure to check out that post as we will be referencing the terms/methodologies we introduced there in this post.
Previous Flow
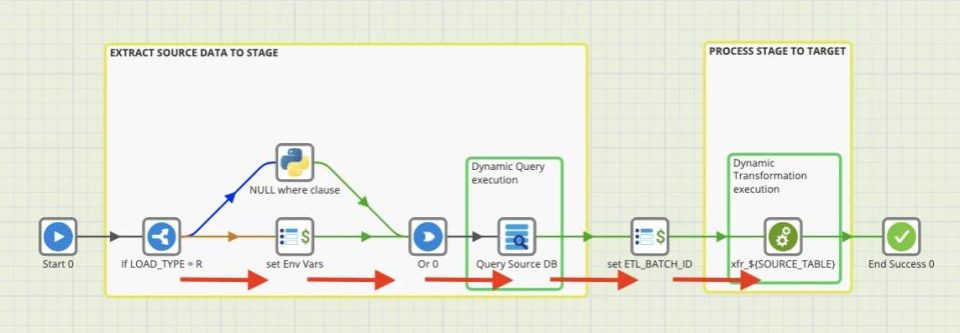
The main part of this orchestration which makes it reusable for all tables is the Query Source DB component, which uses ${SOURCE_TABLE} variable to dynamically extract data from our source, and the xfr_${SOURCE_TABLE} run transformation component which we have cleverly named to dynamically execute the corresponding Matillion transformation based on the value our ${SOURCE_TABLE} variable evaluates to at run time.
This model works well and saves us from creating separate orchestrations for each table we load from our source but we are stuck creating simple, almost identical, transformations whenever we add a new table to our ingestion flow. Additionally, one of the components we use in this transformation requires an existing table to upsert incremental data. This means part of this development process is to manually create a target table for any new tables prior to productionalizing the change.
Today I’ll show you how to cut out both of these steps so our stage to target transformation is reused for every table and our target table is automatically created for new tables, further eliminating repetitive steps when you add tables from your source system. For this we’ve made some modifications to our orchestration.
Orchestration Changes
For the most part our process is the same in that we are still staging our source data and using that staged data to update our target table. We do need to make some changes/additions to support the reusability of our stage to target transformation. Below are the changes we made to our orchestration:
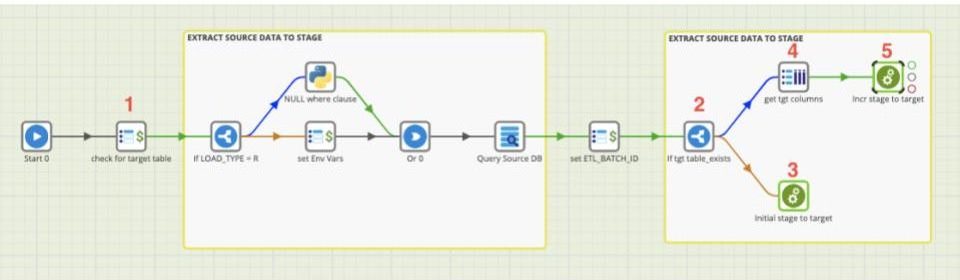
- We check our database’s information_schema to see if the ${SOURCE_TALBE} table exists in the target schema.
- Using an If component we route our process based on the results of the check in change 1.
- Any new tables (that do not exist in the target schema) are routed to an Initial stage to target transformation which creates a target table for us.
- Any existing tables are routed to a component which queries our ${SOURCE_TABLE}’s metadata and stores column names of that table in a ${TGT_COLUMNS} grid variable.
- Finally a Incr stage to target upsert transformation is run using the ${TGT_COLUMNS} grid variable to map staged data to our target table.
Transformation Changes
The major changes to the job are in the transformations we use to move stage data to the target table. We now have 2 reusable transformations Initial stage to target and Incr stage to target. Let’s take a closer look at these transformations.
Initial stage to target
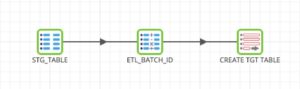
This transformation is run for new tables introduced to the ingestion process. We are using a freeform SQL component in place of the standard Table Input component allowing us to run a dynamic query that selects all of our stage data for the ${SOURCE_TABLE} that is being evaluated at runtime. Below is the query for reference.

After adding ETL_BATCH_ID to the stage data, we move to CREATE TGT TABLE; a Rewrite Table component which creates a table based on the input received from the previous component. See this components parameters below:
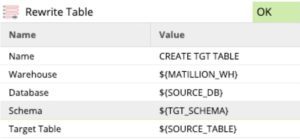
We have not hard coded any of the parameter values allowing for dynamic execution for the new ${SOURCE_TABLE}. This simple transformation eliminates the need to create a target table when adding a new table to our metadata ingestion.
Incr stage to target
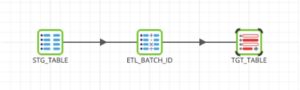
This transformation is run for tables that already exist in our target schema and is very similar to the Initial stage to target transformation run for new tables with the exception of the final component, TGT_TABLE, which has been swapped out for a Table Update. This is the exact same component we use in the previous implementation of this pattern to support the “Always On” methodology introduced in part 1 of this series. However, we have replaced certain parameters with variables for dynamic execution.
Original Upsert Component
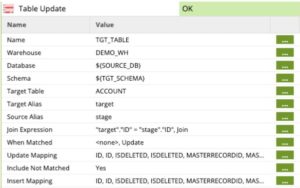
Revised Upsert Component
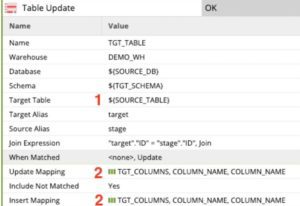
- ${SOURCE_TABLE} has been used in place of the explicit table reference to dynamically insert the table name.
- The ${TGT_COLUMNS} grid variable populated by our orchestration change (#4) is used in the Update and Insert mapping allowing for dynamic mapping of the target table’s columns.
With this we have eliminated the need for table specific transformations which we leveraged previously in this pattern.
Conclusion
Here we showed you how to further automate the development process of a pattern we introduced previously by leveraging some of the advanced features provided by Matillion like grid variables, flow components(If), and table metadata queries.
As with anything there are pros and cons to this approach. One obvious pro is the further elimination of repetitive development steps when bringing in new tables from your source. A potential con is introducing a layer of complexity which makes the data pipeline less “readable” for other developers. For our clients we consider these trade offs and implement the solution that fits best the project, communicating every step of the way.