Ask a data consultant whether you should consider Databricks or Snowflake as the centerpiece of your data infrastructure and the response you’ll most likely receive is: “It depends.” The phrase is used so frequently in our line of work, we often say it to each other half-jokingly as a response to anything.
- “Should we use Sigma or Looker as our BI tool?” It depends.
- “Is data mesh or data fabric better?” It depends.
- “Who would win, Batman or Superman?” Actually that one’s easy: Batman all the way.
We aren’t trying to be intentionally coy or dodge the question. The reality is, while we may all have our own preferences, selecting the best cloud data platform for your organization depends on several factors.
How to Compare Databricks vs Snowflake
When helping our clients choose between Databricks vs Snowflake, we consider factors like:
- Which other tools do you currently use or plan to implement?
- What are your organization’s current and expected future data competencies?
- What do you plan or hope to do with your data after building a cloud data warehouse or data lakehouse?
In this article, I’ll share a breakdown of how I frequently describe the most significant differences and relative strengths of Databricks vs Snowflake. Additionally, I’ll provide some considerations to take into account when selecting which tool best supports your organization’s needs.
Databricks vs Snowflake Comparison
Use the links to navigate through various parts of our comparison.
- Part 1: Architecture and Design
- Part 2: Integrations
- Part 3: Data Sharing
- Part 4: Data Science Support
- Part 5: Cost
- Part 6: Performance
We’ll wrap up with some final thoughts on how to choose the best cloud data platform for you.
Let’s dig in!
Part 1
Architecture and Design
In order to understand how Databricks vs Snowflake differ today—and how they both continue to evolve—it’s helpful to have a basic understanding of their respective histories.
The creators of Apache Spark founded Databricks in 2013, while data warehousing experts from Oracle and Vectorwise founded Snowflake in 2012.
In a sense, both products were designed around overcoming the shortcomings of the Hadoop data lake paradigm, which was popular in the world of big data at that time. Both Snowflake and Databricks center around the concept of separating storage from compute.
The most important difference in their origin stories, however, is that Snowflake was incepted as a massively scalable data warehousing solution for working with structured and semi-structured data. Databricks, on the other hand, was intended to be the ultimate platform for working with data on your data lake—including structured, semi-structured, unstructured, and streaming data.
In other words: Snowflake was originally built primarily by and for data warehousing professionals, while Databricks was originally built primarily by and for data scientists.
UI
Snowflake is centered around working in SQL (or at least, in a more traditional SQL environment).
It looks and feels in many ways like a modern, cloud-centric data warehouse should. It has an easy-to-navigate UI that will likely feel intuitive for anyone who has spent time working in traditional SQL-based platforms.
Databricks, on the other hand, uses a notebook-based interface. This will be more familiar to users with a data science background—particularly if they have experience working in iPython style notebooks. Its notebooks can include multiple languages (Python, R, SQL, and Scala) and data can be easily passed between languages and data structures via Spark dataframes, allowing for a wide range of flexibility.
Databricks also automates many aspects of managing and optimizing Apache Spark, which is powerful but complex to use. This can make big data tasks more accessible to teams without deep Spark expertise.
Ease of Use
Evaluating “ease of use” depends largely on your team’s existing skills and the specific tasks you need to perform.
Databricks might have a steeper learning curve, especially for those not already familiar with how to leverage Spark dataframes or programming languages like Python or Scala. Users with a background in SQL and traditional data warehousing may find Snowflake more intuitive.
Since both products are now competing head-to-head to be the cloud data platform at the center of your infrastructure, it’s unsurprising that they have started to cross paths and meet in the middle.
New Features
Snowflake has recently added features like Snowpark—which allows you to work on data in Python, Scala, or Java in addition to SQL—and Snowpipe, which allows for loading data in micro-batches, enabling data streaming.
Databricks, for its part, has tremendously upgraded its data warehousing capabilities with new features that bring it into much closer parity with Snowflake’s warehousing capabilities.
Delta Lake is an open source protocol that Databricks developed and integrated into its data platform. Delta Lake provides ACID transactions, scalable metadata handling, and unified streaming and batch data processing on top of your existing data lake. And Unity Catalog provides a unified data governance solution for your lakehouse.
In case you’re not familiar with the term “lakehouse,” it’s what Databricks uses to distinguish their open-source architecture design from traditional data warehouse architectures. We’ll dive into the differences in the next section.
Data Warehouse vs Data Lakehouse
From a data storage perspective, there is a critical distinction between Snowflake vs Databricks. Databricks was built to work in concert with data lakes. From this, the term “data lakehouse” emerged as a new approach to data architectures. It combines elements of data lakes and data warehouses to leverage the strengths of both.
What is a Data Warehouse?
A data warehouse is a structured repository of integrated, cleaned, and processed data from various sources. This data is typically stored in a columnar format, which is optimized for SQL-based querying and analytics. Data warehouses are highly efficient for business intelligence tasks like reporting and dashboarding, supporting complex joins, aggregations, and performing well for read-heavy workloads.
However, traditional data warehouses often struggle with handling unstructured or semi-structured data. They may not be ideal for advanced analytics like machine learning that require different data formats, and they might not scale as cost-effectively as data lakes when dealing with massive data volumes.
What is a Data Lakehouse?
Databricks uses the term “lakehouse” to distinguish their open-source architecture design from traditional data warehouse architectures. A data lakehouse combines elements of data lakes and data warehouses to leverage the strengths of both. It maintains the raw, granular, and diverse data storage abilities of a data lake, while incorporating the transactional consistency, schema enforcement, and performance optimizations typically found in a data warehouse.
A data lakehouse can support both structured and unstructured data while still handling large volumes of data cost-effectively, plus provide support for diverse querying methods on the same data (like SQL, Python, Scala, and R for analytics and machine learning workloads). It does all this while providing reliable, high-quality data through schema enforcement and transactional support.
Databricks uses the image below to illustrate the concept of a data lakehouse.
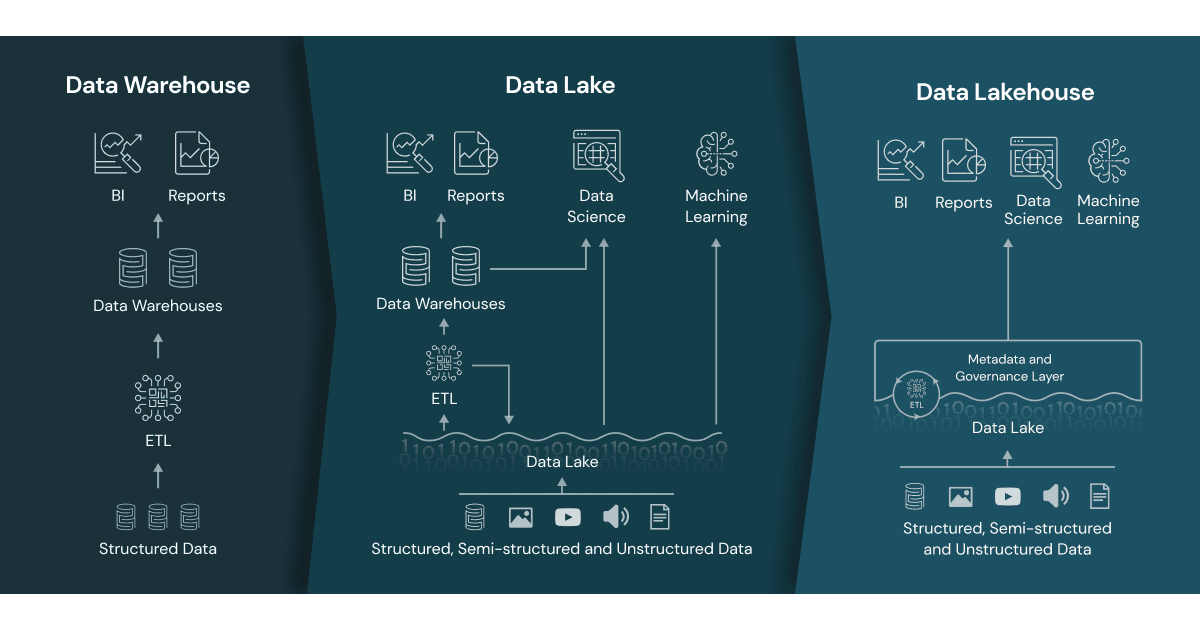 Maybe this is a good time to tell you: I’m a big fan of the data lakehouse design. But I also have a background in data science and am accustomed to working with many different data types, not just structured data. So I see a huge benefit in being able to access all that data from a single location while still retaining the benefits of a classical data warehouse. That said, not every data team needs to work with unstructured data.
Maybe this is a good time to tell you: I’m a big fan of the data lakehouse design. But I also have a background in data science and am accustomed to working with many different data types, not just structured data. So I see a huge benefit in being able to access all that data from a single location while still retaining the benefits of a classical data warehouse. That said, not every data team needs to work with unstructured data.
Snowflake and Databricks both offer orders of magnitude improvement over legacy “on-prem” systems for storing and analyzing data. Both are cloud-agnostic and compatible with multiple cloud platforms including AWS, Azure, and Google Cloud Platform. This gives users flexibility in their choice of cloud provider.
The Bottom Line
Snowflake designs its architecture to provide a high-performance, easily scalable, and simple-to-use data warehousing and analytics solution. It’s putting an increasing focus on developing its data processing and machine learning capabilities.
Databricks, on the other hand, provides a comprehensive platform for big data processing, analytics, and machine learning. It is putting an increasing focus on its data warehousing and governance capabilities, which already rival that of Snowflake’s.
Part 2
Integrations
Snowflake and Databricks both provide numerous integrations with various tools and technologies in the data ecosystem to serve different needs, ranging from data ingestion and ETL to business intelligence, advanced analytics, and data applications.
Data Ingestion & ETL
Snowflake partners with several data integration and ETL providers to help ingest, transform, and load data, including Fivetran, Matillion, Airbyte, Informatica, Talend, and others.
Because Databricks is essentially a web-based platform for utilizing Apache Spark and working in SQL, Python, Scala, or R, it enables users to orchestrate custom API calls written in any of the aforementioned languages. This reduces the need for reliance on third-party vendors—if you have the staff to build and maintain that code. If you don’t, it also integrates with most of the same ETL providers as Snowflake, including those mentioned above.
Both Snowflake and Databricks also work natively with cloud object storage containers, such as Amazon S3 and Azure Blob stores.
Finally, both platforms integrate with data preparation and transformation tools including dbt (data build tool). Each one is also fully capable of orchestrating data preparation and transformation jobs on its own.
BI & Visualization
Both Snowflake and Databricks can integrate with many Business Intelligence (BI) and data visualization tools such as Sigma, Tableau, Looker, Power BI, Qlik, and others. This allows users to create visual reports and dashboards from their data warehouse or lakehouse.
Databricks also provides a native visualization feature in its notebook environment, as well as the ability to combine several visualizations into dashboards that are viewable from within the platform.
Data Science & ML
Databricks provides native support for many machine learning libraries including TensorFlow, PyTorch, and Scikit-Learn. It also integrates with MLflow (an open source package developed by Databricks) for managing machine learning workflows.
Snowflake supports integrations with popular data science platforms and tools—including Databricks—as well as DataRobot, Alteryx, and others. This facilitates more advanced analyses and the building and maintaining of machine learning models.
Data Governance and Security
Both Snowflake and Databricks integrate with data cataloging and governance tools such as Alation, Privacera, and others to help users manage and secure data.
Part 3
Data Sharing
Data sharing is a critical capability in modern data architectures. It enables users to collaborate, exchange data between systems, and create shared data resources to use for a variety of applications and analyses.
Snowflake Data Sharing and Data Exchange
Snowflake provides native functionality for secure data sharing known as Data Sharing and Data Exchange. Snowflake’s architecture allows users to instantly share data without duplicating it. This can save storage costs and eliminate the time typically associated with data transfer.
To accomplish data sharing in Snowflake, users grant other Snowflake accounts access to database objects (tables, schemas, databases). This makes the data available in a read-only format to the consumer, ensuring the integrity of the original data.
Data providers have complete control over who can access their shared data and can revoke access at any time. Consumer accounts do not pay for the compute resources the provider account uses, and vice versa.
Furthermore, the Snowflake Data Marketplace allows organizations to share and consume live, ready-to-query data from various business and public data sources.
Delta Sharing
Databricks leverages Delta Sharing, an open protocol for secure data sharing which is designed to be easy, safe, and open. Databricks provides it as an open source library, along with Delta Lake and MLfLow.
Delta Sharing is the industry’s first open protocol for securely sharing data across organizations in real time, regardless of the platform. By being open, it ensures that it can be implemented in any system, providing compatibility and preventing vendor lock-in.
Although it is open source, the protocol includes robust security features. It enables fine-grained access control, ensuring that recipients can only access the data they are permitted to see. It also encrypts all data transfers for additional security.
Like Snowflake Data Sharing, Delta Sharing aims to make data sharing as easy as possible. With it, you can share a subset of data with a few simple commands, and recipients can read the shared data using standard tools like Python, SQL, and so on.
Also like Snowflake Data Sharing, Delta Sharing enables sharing of live data. This means that when the data is updated at the source, all authorized consumers can immediately see the changes. This eliminates the need for periodic data dumps and syncs, ensuring that everyone always has the most up-to-date data.
Since both data sharing protocols allow for data to be shared directly from the source without making copies, they can save significant storage costs. They also reduce the network costs and latency associated with moving large amounts of data.
Part 4
Data Science Support
While both Snowflake and Databricks offer data science capabilities, they have different levels of support and are suited to different types of tasks.
Snowflake Data Science Support
Snowflake is primarily a cloud data warehousing platform, and it’s optimized for storing and querying large datasets. It uses SQL for querying, which is widely used for data analysis.
For data scientists who primarily work with SQL, Snowflake offers an environment that can handle large data volumes efficiently, with easy scaling and robust concurrency support.
Snowflake also integrates with a range of data science and machine learning tools, such as Python, R, and various BI tools. You can connect these tools to Snowflake to pull in data for analysis.
The goal of Snowpark is to allow developers, data engineers, and data scientists to write code in their preferred programming languages and execute that code directly within Snowflake’s platform. This extends the capabilities of Snowflake beyond SQL to include other languages, such as Python, Scala, and Java.
Before Snowpark, it was much more time-consuming to perform operations that are not easily accomplished with SQL. Developers often had to extract data, use different tools to process it outside of Snowflake, and then load the processed data back into Snowflake. This can be inefficient and may also introduce latency. Snowpark aims to address this problem by allowing users to perform more complex data transformations and analytics tasks directly in Snowflake.
With Snowpark, developers can use familiar programming concepts such as DataFrames and user-defined functions (UDFs) to perform operations on their data. Additionally, Snowflake’s powerful processing capabilities and architecture allow for executing computations close to the data.
Databricks Data Science Support
Databricks is designed to be a unified platform for data preparation, warehousing, analytics, and machine learning. This makes it a stronger choice for more advanced data science tasks.
Databricks supports multiple languages that are common in data science, including Python, R, SQL, and Scala. This allows data scientists to work in the language they are most comfortable with.
Databricks includes built-in support for creating machine learning models, including integration with popular libraries like TensorFlow, PyTorch, and scikit-learn.
The collaborative notebooks feature in Databricks allows data scientists to work together more easily, sharing code and results in real time.
Databricks also integrates with MLflow, an open-source platform for managing the end-to-end machine learning lifecycle. This includes experiment tracking, model versioning, and deployment support.
The Bottom Line
While both platforms offer data science capabilities, Databricks is generally better suited to more advanced data science tasks, particularly those involving machine learning. On the other hand, Snowflake offers robust support for SQL-based analysis and can handle large data volumes efficiently—plus it integrates with a range of third-party data science and machine learning tools.
As always, the best choice depends on your specific needs and the skillset of your team.
Part 5
Cost
Both Snowflake and Databricks use consumption-based pricing models, where the cost depends on the amount of resources used. However, there are important differences in how they structure their pricing.
Snowflake Pricing
- Snowflake separates the costs for storage and compute. The amount of data stored in Snowflake determines the storage cost, and you pay for the usage of compute resources (referred to as “virtual warehouses”).
- You can start, stop, and resize the virtual warehouses at any time, which allows for greater flexibility in managing costs. You only pay for what you use, down to the second.
- Snowflake also offers different pricing tiers, which come with different capabilities and performance characteristics.
Databricks Pricing
- Databricks pricing is also based on the consumption of resources, where you pay for the Databricks Units (DBUs) consumed by your workloads. A DBU is a unit of processing capability, per hour.
- You can control costs in Databricks by managing the size and type of the clusters you use. You have the option to use on-demand or spot instances, and can automatically terminate clusters when idle to save costs.
- Similar to Snowflake, Databricks also has different pricing tiers, which come with different features and capabilities.
- Databricks uses cloud object storage such as Amazon S3 or Azure Data Lake Storage, which are among the most cost-effective means of data storage available. Because of this, it actually does not bill you for any storage costs. Instead, it incurs those costs to your chosen cloud provider (e.g., AWS, Azure, or GCP).
The Bottom Line
It’s important to note that both Snowflake and Databricks offer dynamic scalability—meaning you can add or subtract resources as needed—which can help manage costs. The total cost can vary based on the specific use case, scale of data, and efficiency of resource usage.
Be sure to consider the potential hidden costs. These might include costs associated with data transfer, data ingestion and egress, and management and operation of the system (which may also be impacted by the existing resources and capabilities within your team).
Of course, pricing structures can change and discounts or other factors may apply to your situation. Because of this, we recommend checking the most recent and detailed pricing information on the official Snowflake and Databricks websites, or contacting their sales teams for more specific pricing information.
Part 6
Performance
Both Snowflake and Databricks have hotly contested each platform’s performance in recent years. Performance can vary significantly in each platform depending on the type of workload, data volume, and specific use case.
Similarities
Both systems are designed to handle large data volumes and offer several features to help improve performance.
Both platform’s architectures separate storage and compute resources. This means you can scale your compute resources up or down independently of your data volume, allowing for flexible and potentially efficient data processing.
Both platform’s also make use of a multi-cluster shared data architecture. When a single query is demanding a lot of resources, users can configure Snowflake and Databricks to automatically spin up additional compute resources to handle the load. This ensures consistent performance.
Snowflake and Databricks also provide automatic optimizations such as caching, clustering, and pruning to improve query performance.
Differences
For very complex transformations or advanced analytic workloads such as machine learning, Snowflake might not perform as well as Databricks due to its emphasis on SQL-based operations.
Databricks is based on Apache Spark, which is well-regarded for its speed when processing large datasets, especially for complex transformations and machine learning tasks.
Databricks has made several optimizations to the standard Spark runtime to improve performance. This includes enhancements for caching, indexing, and query optimization.
Databricks also provides an optimized version of Spark that includes additional performance enhancements and integrations with other performance-oriented technologies such as Delta Lake.
The skill level of the team can also sometimes influence Databricks’ performance. Properly tuning Spark to get maximum performance can be complex and require a deep understanding of Spark’s internals.
The Bottom Line
The performance of Snowflake and Databricks can depend heavily on the specifics of your workload, data, and team skills.
Snowflake’s performance may be more consistent and require less tuning thanks to automatic optimizations. Databricks, meanwhile, has the potential to provide superior performance for complex data transformations and machine learning workloads, but may require more expertise to tune optimally.
The Big Picture
How to Choose the Best Cloud Data Platform for You
One way of thinking about the current differences between Snowflake vs Databricks is to liken them to a chef’s knife versus a Swiss Army Knife. The analogy is far from perfect, but let me explain…
Snowflake is like a chef’s knife…
It is highly specialized and efficient at what it does—in this case, cloud data warehousing. Its design allows it to cut through large volumes of data with ease, making it great for SQL queries and analytics on structured and semi-structured data.
Its key selling points are speed, scalability, and ease of use for these specific tasks, much like how a good kitchen knife is prized for its sharpness, balance, and handling.

Databricks is like the Swiss Army Knife of cloud data platforms…
In the right hands, Databricks can handle any amount of data slicing and dicing just as easily as Snowflake. However, its capabilities extend far beyond that. It includes multiple tools for different data tasks—from data ingestion to analysis to machine learning.
It’s more versatile, supporting multiple languages (e.g., Python, Scala, SQL, and R) and a broader range of data tasks. It also comes with collaborative notebooks, making it a handy all-in-one tool for data engineering, data science, and machine learning.

Which would you choose?
In the same way a chef would prefer a specialized kitchen knife, many data engineers who are accustomed to working primarily in SQL environments might prefer Snowflake’s familiarity and ease of use as a cloud data warehouse. Indeed, it’s an excellent tool for that task.
However, to be blunt (if you’ll indulge me with one blade pun), this is where the analogy falls short. Databricks is a vastly superior tool for data warehousing and analysis than, say, a Swiss Army Knife would be in the kitchen.
Snowflake might be your tool of choice if:
- The task at hand is data warehousing with a side of analytics
- You don’t see a need for working with any unstructured data types
- You have other tools readily available for tasks like data ingestion and machine learning
Databricks may be more suitable for you if you:
- Require a wide array of data tasks, from data building end-to-end pipelines to data science and machine learning
- Are working with structured data as well as unstructured or semi-structured data
- Want to empower your team to manipulate data with multiple languages and data structures (in Spark, SQL, Python, Scala, and R, for example)
So which is the best cloud data platform, Snowflake or Databricks?
Your specific use cases, your team’s skills, and the range and complexity of the tasks you need to perform should guide your choice.
In other words: it depends. 🙂
Need Help with Your Data Architecture?
Lay the technical foundation for your data journey with Data Clymer’s modern data architecture services. Our data architects specialize in helping clients design and implement a modern data architecture that aligns with their organization’s goals. We partner with Databricks, Snowflake, and other leading tools to build modern cloud data systems for organizations of all sizes. Contact us today to get started.