Introduction
This article is a continuation of my recent piece about continuous integration (CI). In this article I will talk about another critical piece of the DataOps equation: continuous deployment (CD). Like I did with CI, I will talk about what CD is, why it is important for data teams, and how it can be implemented in a dbt project using dbt Cloud.
What is Continuous Deployment?
CD is a process that uses automation to validate and test if changes to a codebase are correct before automatically deploying those changes to a production environment. Since this article will be in the context of a dbt project that uses dbt Cloud, the production environment will typically be a production database or schema in a cloud data warehouse such as Snowflake.
Why is Continuous Deployment important for data teams?
CI is the first step in an automated deployment process where changes to a codebase are tested and reviewed prior to being merged into a production branch. Once those changes are merged, developers need an autonomous process to push those changes to their data warehouse’s production environment.
This hands-off process builds changes on a scheduled cadence allowing data teams and their stakeholders to know when to expect those changes to be live. This automation eliminates relying on someone to manually complete this process. Needless to say, that process would be error prone and resource-intensive – eliminating the human factor means more time for teams to spend on solving business problems.
The Continuous Deployment Process
The CD process extends the CI process that I outlined in my previous article. Once changes are pushed to the remote repository and the CI process finishes, the code can be merged into the production branch and a basic configuration of dbt Cloud can release those changes in an automated fashion. Below is a complete look at an end-to-end CI/CD lifecycle:
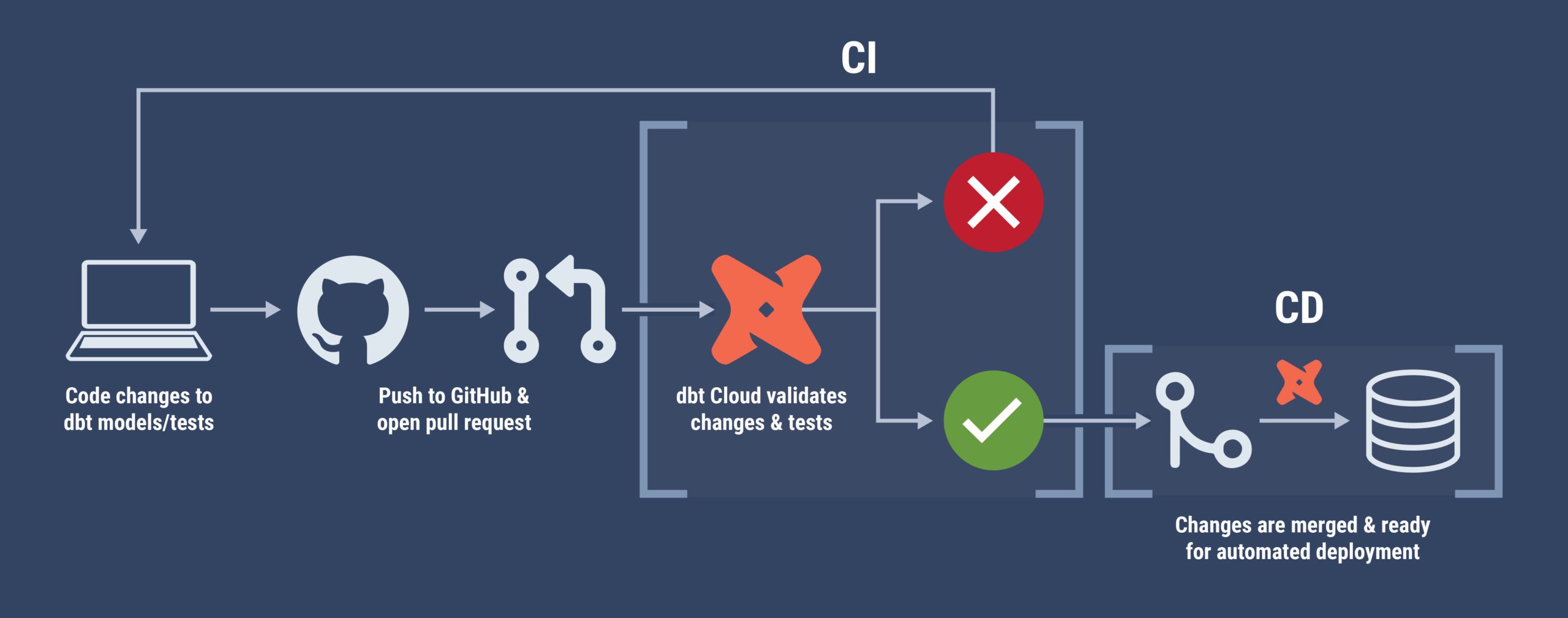
- Developer makes changes to existing dbt models/tests or adds new ones
- Changes are pushed to GitHub and a pull request is opened which triggers a special CI job in dbt Cloud. This CI job validates that the models compile successfully in a production-like environment and that all tests pass
- (If applicable) Code review occurs to ensure that the proposed changes meet the project’s standards
- Changes are merged into the production branch
- On the next dbt Cloud run, dbt will pull the latest version of the project and build any new additions or changes
dbt Cloud
Like I mentioned above, a basic setup of dbt Cloud already enables the CD process. In this section I will talk about a previous experience of mine and how dbt Cloud was configured to handle scheduled automated deployments.
Part of configuring dbt Cloud involves connecting a GitHub repository (or GitLab, BitBucket etc) – when dbt Cloud jobs run, they pull the latest version of the dbt project from the version control system. From there, it is just a matter of configuring schedules for the dbt Cloud jobs and with each run, new additions and/or changes to the project get deployed.
In my previous experience, the dbt Cloud job that built and deployed to the production environment in Snowflake was scheduled to run twice per day: once at 8 AM ET and again at 10 PM ET. The 8 AM run was to refresh the warehouse prior to the team beginning the work day and the 10 PM run was to deploy any additions/changes that were merged throughout the day. By using this schedule the data team and its stakeholders knew when to expect deployments with little to no manual oversight required.
Conclusion
Automation helps data teams work better and opens up more time to work on impactful projects. A CI/CD pipeline pays dividends in the long-run by enabling data teams to be confident from the time code gets typed into a text editor all the way through seeing the models in the data warehouse and beyond that their work is tested, trusted and validated.
Data Clymer is a top-rated dbt Labs consulting partner and one of only five dbt Labs premier partners. We’ve helped customers like Harvard Business Review, Vida Health, Drata, Kentik, and many more maximize the value of their dbt implementations.
If you would like to have Data Clymer help you with the set-up of your CI / CD environment, please fill out this form.

Zak is a cloud data engineer focused on using his experience with SQL and Python to build analytics tools that help solve business problems.