What did we learn at the Databricks Data+AI Summit this year? Way too much to cover with detail in this blog post. However, I’ll walk you through the key highlights—and there were a lot of them. From exciting new feature announcements like LakehouseIQ and AI Functions to long-awaited releases such as the Databricks Marketplace and Clean Rooms, I walked away from this year’s conference feeling more excited than ever about the current speed of innovation and the future of data.
If you’re curious about the Snowflake conference that took place the same week, check out my colleague Jesse McCabe’s recent article on key takeaways from the 2023 Snowflake Summit.
A lot to cover here, so let’s dive in! Here are the 6 hottest topics from the 2023 Data + AI Summit, plus my insights on the future of data.
1. LakehouseIQ
One of the more interesting and surprising announcements for me at this year’s summit was the upcoming release of LakehouseIQ, a unique in-platform AI feature. It consolidates information from your data, code, documentation, usage patterns, and even your organizational chart to understand and respond to natural language inquiries about your data. Additionally, it comprehends unique business terminologies.
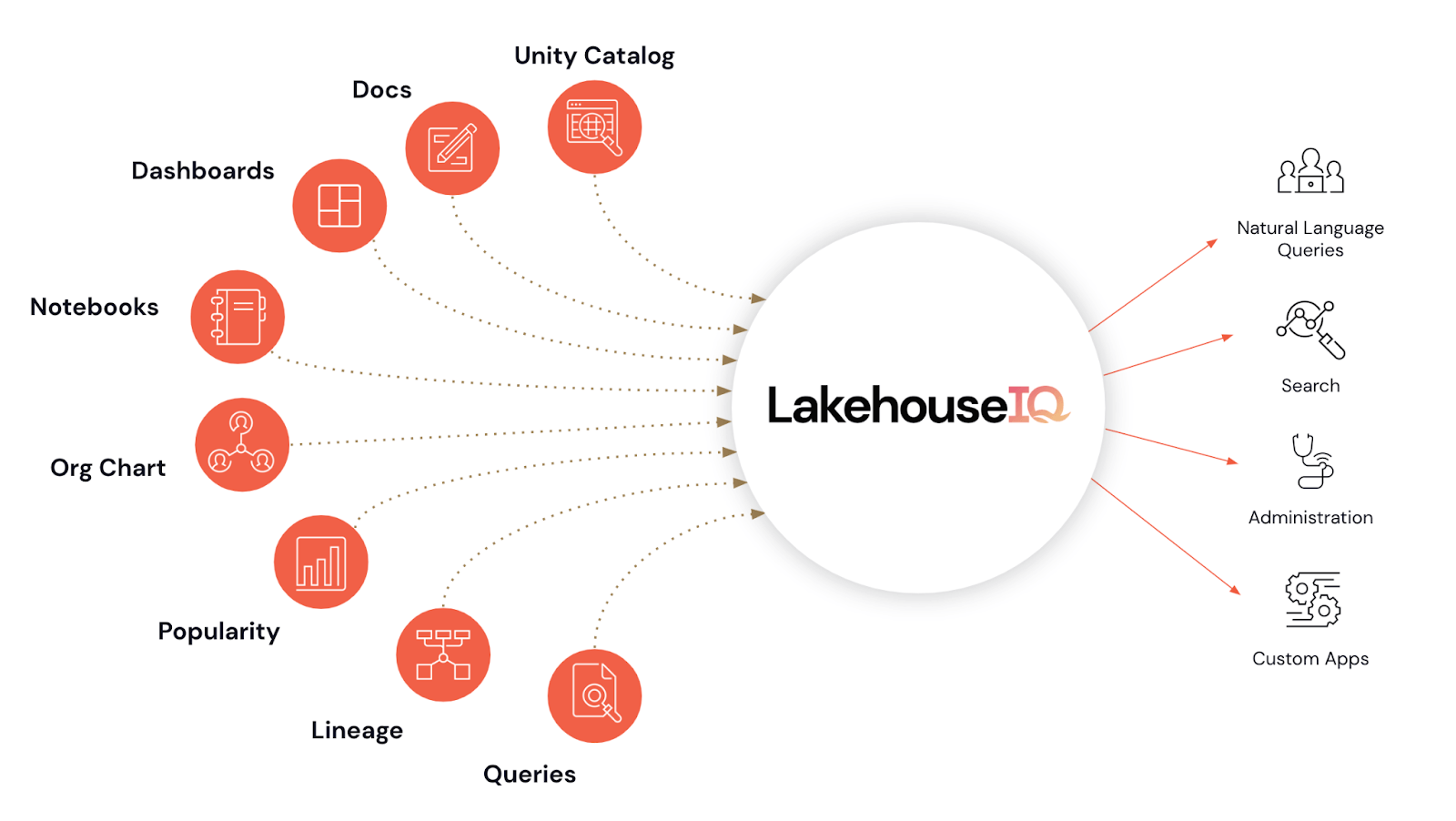
Built on your data and metadata, LakehouseIQ promises significantly enhanced answers compared to the use of native Large Language Models (LLMs) alone. It empowers any member of your organization (given the correct permissions) to search, comprehend, and query your unique data using natural language.
Here are a few key things that set LakehouseIQ apart from other LLM-based analytics tools:
- It leverages signals from the entire Databricks Lakehouse platform, which include Unity Catalog, dashboards, notebooks, data pipelines, and documentation. The aim is to understand how data is used in practice and build highly precise specialized models for your organization. This process respects the unique datasets, jargon, and internal knowledge within each company.
- Users only receive results from the datasets to which they have access.
- Users can write natural language queries in the SQL Editor and Notebooks. LakehouseIQ even directly answers questions posed in natural language.
- It significantly enhances Databricks’ in-product search by interpreting, aligning, and presenting data in an actionable, contextual format. This accelerates users’ initiation with their data.
- When writing comments and documentation, LakehouseIQ offers automatic suggestions. The more documentation you provide, the more helpful these suggestions become, thanks to access to additional data.
- LakehouseIQ also assists in understanding and debugging jobs, data pipelines, and Spark and SQL queries.
- Its main capabilities can be accessed through an API, enabling custom apps to also benefit. It offers integrations into LLM application frameworks like LangChain. Consequently, your AI apps can interact with your data and documents on the Lakehouse in natural language, leading to the development of rich, grounded applications for your business.
How will LakehouseIQ impact data professionals?
Most other enterprise AI apps promise to interact only with your documents, or textual data. This aspect in particular makes LakehouseIQ intriguing to me.
While I don’t believe this tool, or any similar ones, will replace the necessity for skilled analysts and engineers anytime soon, I am eager to see its impact on the way we work. Will it liberate analysts from ad-hoc requests and provide them with additional time for deeper insights? Can it augment engineering tasks, leading to more optimized code? Or will it perceive humans as threats to its existence and initiate a nuclear war decimating most of the population?
I believe it’s the former, and will explain why in a future blog post. Subscribe or follow Data Clymer on LinkedIn to make sure you don’t miss it. 🙂
2. Enhancements for Analysts and Engineers
Databricks released a slew of new features and enhancements to make life easier for analysts and engineers. I’m excited to see how these new features will enhance Databricks’ accessibility to a broader audience, including less technical users.
A few of these include:
AI Functions: Streamlining the use of LLMs in Databricks SQL
Launched for public preview in April, AI Functions provides direct access to LLMs like OpenAI’s ChatGPT from Databricks SQL. This removes the need for complex pipelines or new model requests. It enables users to utilize existing LLMs for tasks like sentiment analysis, language translation, and text summarization.
Expanded AutoML Capabilities
New Lakehouse AI features include support for fine-tuning generative AI models (like LLMs) for tasks such as text classification. AutoML now enables non-technical users to fine-tune models on your organization’s data with relative ease. Technical users can perform these tasks more efficiently. This feature is currently in a private preview.
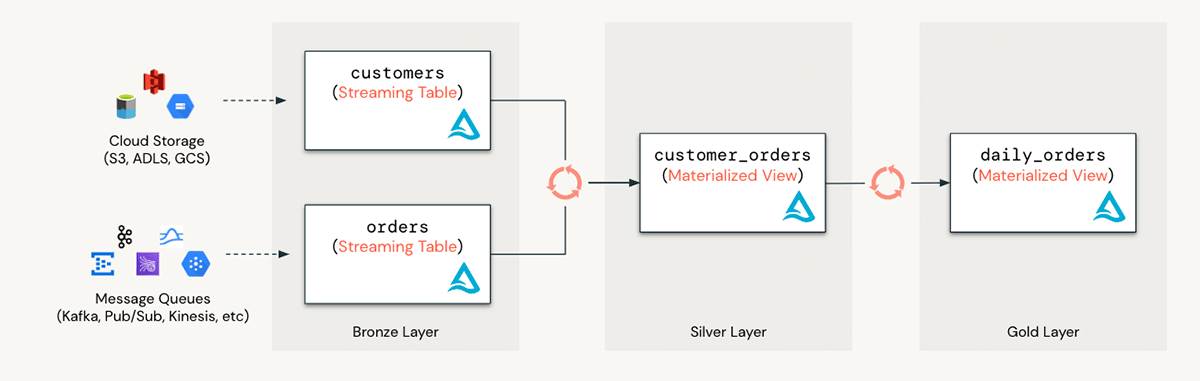
Upgrades to Delta Live Tables Pipelines for Streaming Tables & Materialized Views
Materialized Views, built on Delta Live Tables, reduce costs and improve latency by pre-computing frequently used queries. These views are useful for data transformation, accelerating end-user queries and BI dashboards, and securely sharing data.
Streaming Tables support continuous, scalable ingestion and facilitate real-time analytics, BI, and machine learning. They help engineers and analysts manage high volumes of data more efficiently and make data streaming more accessible with simple SQL syntax.
These Delta Live Tables features are now fully integrated with dbt and compatible with Unity Catalog.

Workflows Enhancements
The Workflows team unveiled next year’s roadmap. Upcoming updates include serverless compute for Workflows and Delta Live Tables Pipelines, improved control flow, cross-team orchestration, and a comprehensive CI/CD flow with full git integration and the ability to express Workflows as Python.
English SDK
Another interesting unveil during this year’s summit was the “English SDK” for Apache Spark. Similar to GitHub Copilot, it will employ generative AI to convert plain English instructions into PySpark and SQL code. Key features include web search based on user description, DataFrame operations guided by plain English instructions, streamlined creation of User-Defined Functions (UDFs), and integrated caching for speed, reproducibility, and cost-saving.
My Wish List
There are also a few other enhancements I would personally love to see in the future. For instance, the addition of standard connectors for Extract-Load (EL) pipelines from third-party data providers would be a significant value-add. Also, I believe there is still room for improvement, and anticipate that efforts will be made to simplify processes like cluster and workspace creation for users who find these aspects of the platform intimidating.
3. Enhancements for Data Providers & Consumers
And here’s where things get really exciting.
Databricks Marketplace is generally available!
I’m thrilled about the launch of the Databricks Marketplace because of its innovative, open concept. The Databricks Marketplace is accessible to any client that can read delta shares, not just Databricks customers. This means data providers can expand their reach while hosting data on a single platform.
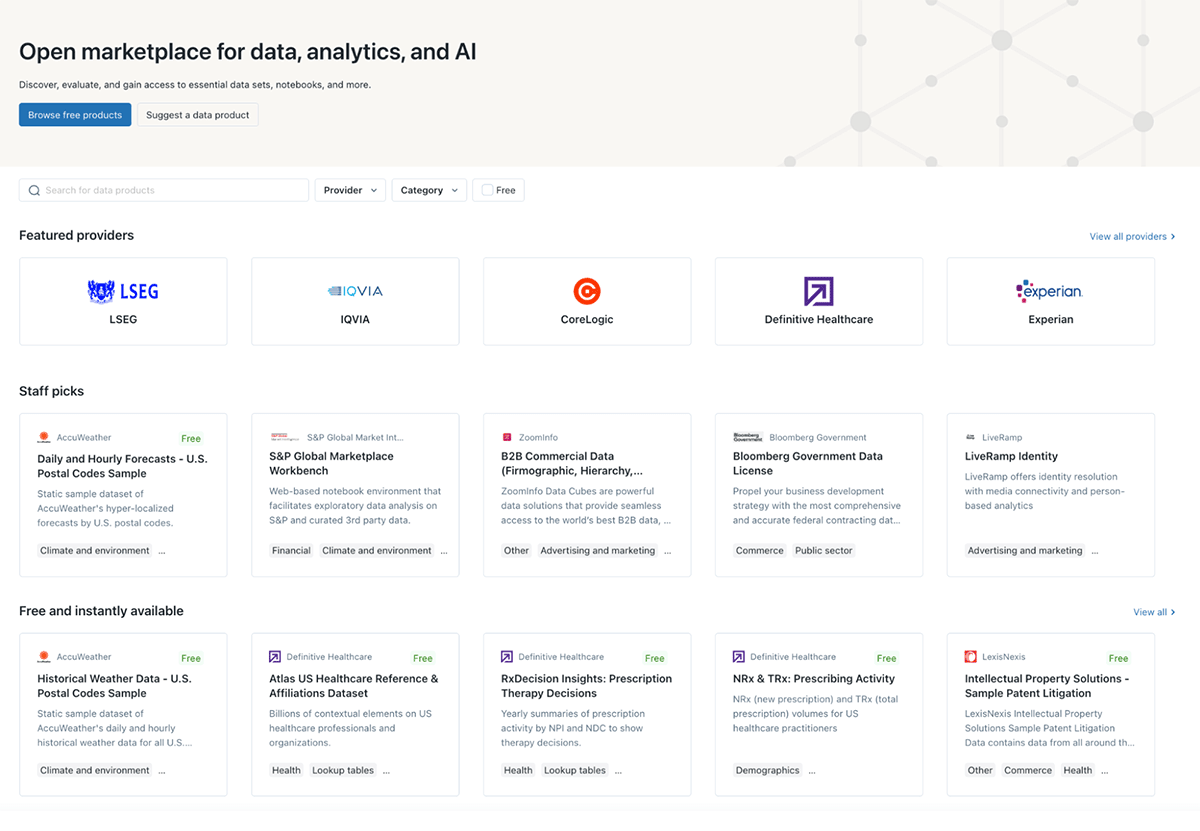
Here’s what you need to know about the Databricks Marketplace.
What is the Databricks Marketplace?
Databricks Marketplace provides a platform for sharing and exchanging data assets, such as data sets and notebooks. This sharing can happen either publicly or within private exchanges across different platforms, clouds, and regions without vendor exclusivity.
The marketplace also allows the provision of pre-built notebooks and sample data. These resources can help potential consumers quickly and confidently evaluate the relevance of a data product for their AI, Machine Learning, or analytics projects.
Coming soon
Databricks will also offer AI model sharing in its Marketplace, facilitating discovery and monetization of AI models for both data consumers and providers. Databricks customers will have access to top-tier models, which can be swiftly and securely integrated with their data. Furthermore, Databricks will curate and publish open-source models for common uses, such as instruction-following and text summarization, optimizing their tuning or deployment on Databricks.
Also coming soon, the addition of Lakehouse Apps will provide users with secure, straightforward access to a broad array of new applications. This will simplify the adoption, integration, and management of data and AI applications. These apps offer a novel way for developers to build, deploy, and manage applications for the Databricks platform. By listing their Lakehouse Apps in the Databricks Marketplace, developers can facilitate wider adoption and allow customers to discover and deploy their software more easily and securely.
Databricks Clean Rooms
Databricks Clean Rooms are now available in Private Preview on AWS.
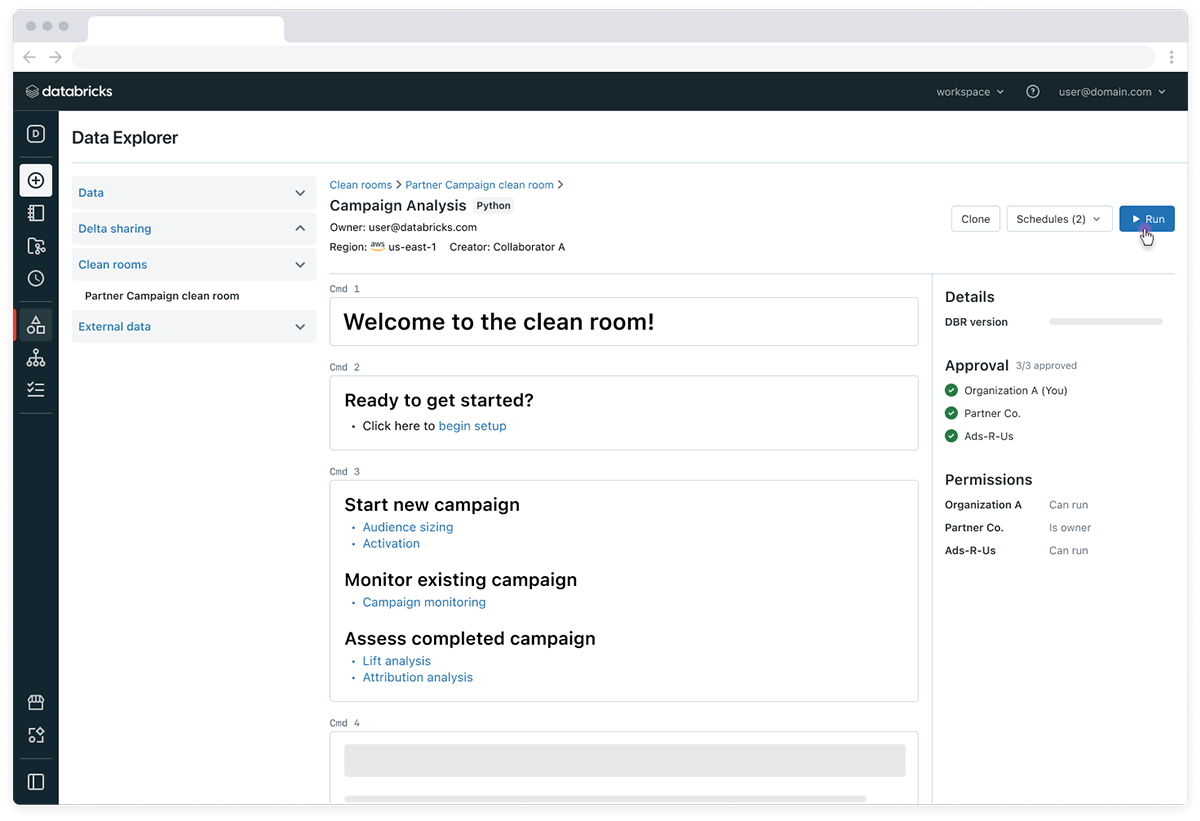
What are Databricks Clean Rooms?
Databricks Clean Rooms offer a secure environment for businesses to collaborate with customers and partners across any cloud platform, with an emphasis on flexibility, scalability, and interoperability.
Unlike other solutions, Databricks Clean Rooms support multiple languages (SQL, R, Scala, Java, Python), facilitating a wide range of tasks from simple analytical workloads, like joins, to complex computations for machine learning. Constructed on the open Delta Sharing platform, users can securely share data without needing to replicate data or commit to a single platform. This feature will take data sharing a step further by enabling secure joint computing.
Data Sharing Updates
More than 6,000 organizations are utilizing Delta Sharing to consume data. Delta Sharing on Databricks facilitates the daily exchange of over 300 Petabytes of data.
Databricks is broadening the Delta Sharing ecosystem with new partners, including Cloudflare, Dell, Oracle, and Twilio. These collaborations aim to streamline data sharing between various platforms such as Databricks, Apache Spark™, pandas, PowerBI, Excel, and any other system that supports the open protocol.
Competition breeds excellence?
Admittedly, a lot of these enhancements seem to be driven by competition with Snowflake, particularly in areas like Marketplace and Apps. However, perhaps it’s thanks to that competitive pressure that Databricks is improving the data sharing model by creating a more open ecosystem.
The same economics that currently encourage platforms like Databricks and Snowflake to innovate and enhance data sharing, discovery, monetization, and consumption suggest that as the volume of data available in these marketplaces expands, the cost of accessing much of this data should decrease, provided the data can be hosted by multiple providers. It will also drive innovation in the applications and ML models available for use on these Marketplaces.
Related Article: Databricks Vs Snowflake: Which Is The Best Cloud Data Platform For You?
4. Enhancements for Data Administrators
Lakehouse Federation will address critical painpoints for clients who have not fully migrated to the Lakehouse yet or still have silos in other data platforms—including MySQL, Postgres, Redshift, Snowflake, Azure SQL, Synapse, and BigQuery as well as other Lakehouse formats like Apache Iceberg.
With the addition of Volumes, our Databricks clients may soon be able to manage and monitor things like access, lineage and usage for all of their data assets regardless of type, format or location. Though, perhaps even more impactful may be the ability to search and discover all of those assets from within Unity Catalog.
Here’s what you need to know about key enhancements for data administrators.
Lakehouse Federation
Data fragmentation across multiple systems remains an issue due to historical, organizational, or technological factors. This can lead to:
- Difficulty in discovering and accessing data across various databases and storage systems, causing incomplete insights.
- Engineering bottlenecks when querying different data sources, as data must be moved to a preferred platform, a time-consuming and sometimes unnecessary process.
- Increased risk of data leakage and compliance inconsistency due to fragmented governance.
Lakehouse Federation aims to address these challenges by enabling organizations to more easily integrate, query, and manage their scattered systems as part of the lakehouse. It provides:
- Unified data classification and discovery, facilitating secure access and exploration of all available data, irrespective of its location.
- Faster ad-hoc analysis and prototyping across all data, analytics, and AI use cases, without requiring data ingestion.
- Improved compliance and tracking of data usage with built-in data lineage and auditability.
- And coming soon: Users will be able to enforce consistent access policies from Unity Catalog to federated data sources, eliminating redundant policy definitions.
Delta Universal Format
Unity Catalog will soon extend its governance capabilities to open storage formats like Apache Iceberg and Hudi with the public preview of the Delta Universal Format (“UniForm”). This will allow Delta tables to be read as Iceberg tables (and soon Apache Hudi), positioning Unity Catalog to support all three major open lakehouse storage formats.
Updates to Unity Catalog
Added support for both Machine Learning (ML) assets and unstructured data to equip organizations for AI compliance. This includes the integration of Feature Stores and Model Registries into Unity Catalog, providing automatic versioning, lineage tracking, and improved visibility across workspaces for key ML pipeline components.
Additionally, a new object type called “Volumes” has been added to catalog non-tabular data such as images, audio, video, and PDF files – enabling the same governance and tracking for all of your tabular and non-tabular data.
AI-Powered Governance
Unity Catalog will also leverage AI itself to streamline data governance. This includes motoring and proactive alerting for data and ML pipelines, including automatic PII detection from Okera (a recent acquisition). It can also auto-generate dashboards and data quality reports.
System Tables will serve as a central analytical store providing cost and usage analytics, audit analytics, and data lineage tracking. Users can query these to turn operational data into valuable insights.
5. Enhancements for Data Science & Machine Learning
Not to stray too far from its roots, Databricks also announced several enhancements to its core Data Science and ML capabilities, specifically around Generative AI and LLMs.
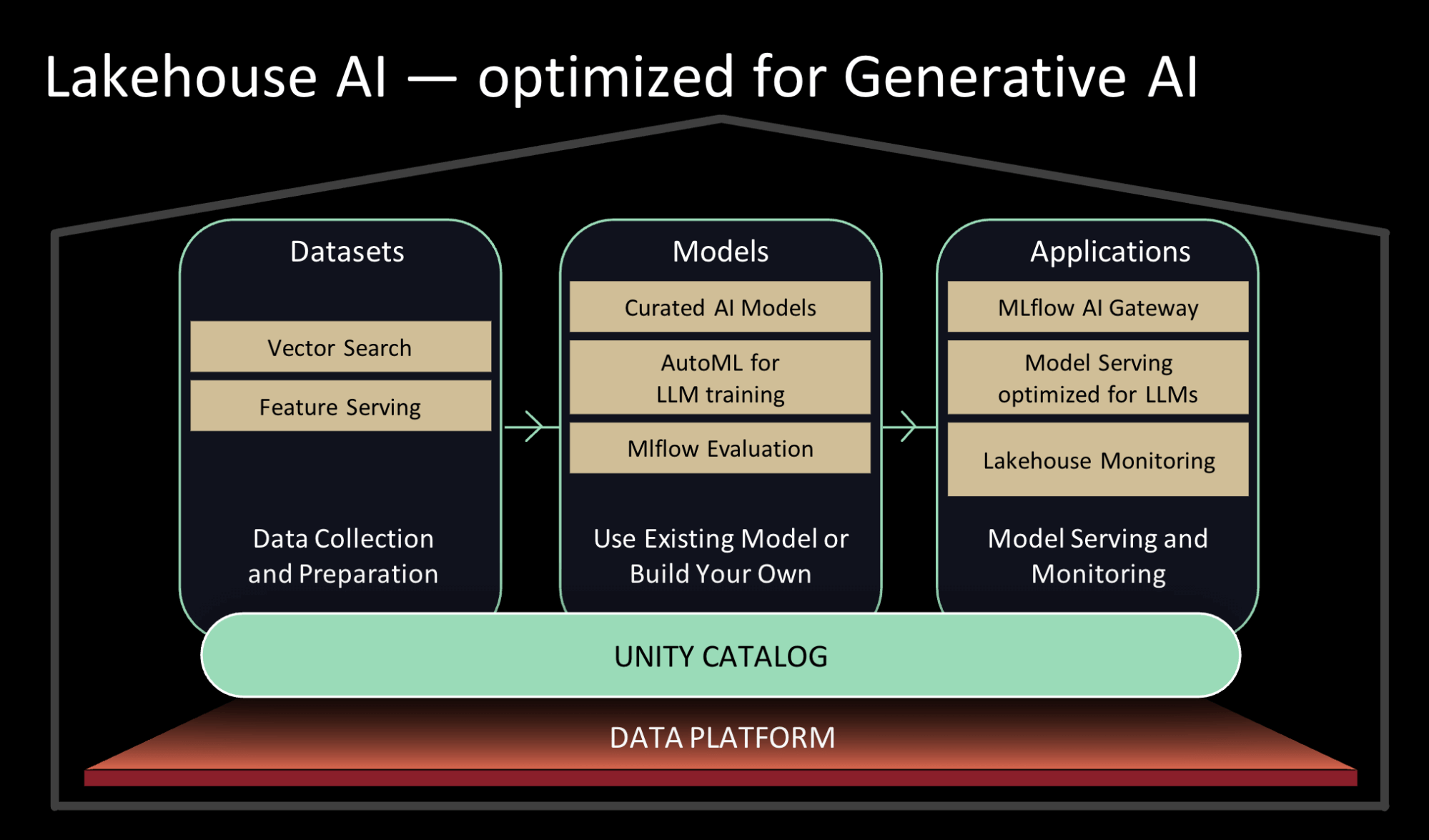
Current challenges in developing generative AI models include evaluating LLMs’ reliability, managing the cost and complexity of training with enterprise data, and ensuring trustworthy models in production. Databricks introduced several new Lakehouse AI capabilities to tackle these challenges. The enhancements will boost data security and governance while expediting the transition from proof-of-concept to production.
New Lakehouse AI capabilities
- Availability of best-of-breed foundational models in the Databricks Marketplace and open-source, task-specific LLMs in Unity Catalog.
- AutoML enhancements for fine-tuning generative AI models like LLMs.
- Prompt engineering tools for optimal prompt template identification.
- Vector embeddings for quick vector similarity searches.
- Optimized GPU serving for top open-source LLMs, reducing costs and enhancing scalability.
- Feature and Function Serving for low latency computations via a REST API endpoint.
- Logging of incoming requests and outgoing responses to model-serving endpoints in Delta tables in Unity Catalog.
- Enabling data analysts and engineers to use LLMs and other ML models within SQL query or SQL/Spark ETL pipelines.
New LLMOps tools
Model evaluation is a crucial component of few-shot and zero-shot learning techniques like prompt engineering. To address challenges like hallucination, response toxicity, and vulnerability to prompt injection, a new set of LLMOps tools for model evaluation has been included in MLflow 2.4, including:
- One-line model tracking command for wide task evaluation with LLMs via mlflow.evaluate().
- MLflow Artifact View for side-by-side comparison of model inputs, outputs, and intermediate results.
- Enhanced MLflow Tracking that displays dataset information in the UI for each run.
What’s next?
What’s next on the horizon largely depends on market demands. This year, LLMs were the hot topic leading up to conferences, resulting in many updates in that area. As for the upcoming year, it remains to be seen what the market (and thus, cloud data platforms) will prioritize.
6. Data Clymer Databricks Partner Awards
Last but certainly not least, I’d be remiss not to mention a couple of our amazing Data Clymer partners who won Databricks Global Partner Awards at this year’s Data + AI Summit:
A hearty congratulations to:
- dbt for winning Databricks Customer Impact Partner of the Year! Databricks’ 2023 State of Data + AI report revealed dbt as its fastest-growing data and AI product of the year, and we’re looking forward to seeing the continuous customer adoption and usage that will stem from the partnership between these two data leaders.
- Fivetran for winning Databricks Innovation Partner of the Year! This award comes on the heels of several successful product integrations. It’s thrilling to see how Fivetran and Databricks work together to help organizations get the most value out of their data.
The Future of Data Utilization, LLMs, and Data Sharing
So who wins here? Everyone.
Databricks is pushing Snowflake to be better and Snowflake is pushing Databricks to be better.
This dynamism opens up new possibilities for advancements in areas like LLMs and AI-assisted analytics, which would have seemed almost unimaginable just a few years ago. I, for one, couldn’t be more excited about the open direction we’re moving in.
In fact, the future of data utilization and making informed business decisions is looking brighter and more accessible than ever.
But even with all the buzz around AI enhancements and LLMs, these pale in comparison to my excitement for increasing data, model, and application sharing tools like Marketplace and Clean Rooms. It’s as if the cloud is evolving into a vast, global data warehouse, with fine-tuned access controls.
As I consider the exciting prospects, a non-fiction book I read nearly a decade ago called The Master Algorithm comes to mind. The closing chapters imagine a future where each individual has an online registry to control which businesses can access and use their data. As a result, companies might have to incentivize us to permit data usage, possibly through payment, creating a global data marketplace where individuals can monetize their own data.
Another idea from the same book is the possibility of highly personalized LLMs—to the point of being a digital version of you. Imagine having a digital assistant that’s not only attuned to all of your nuances and idiosyncrasies, but can also convincingly speak on your behalf. With the emergence of truly open Marketplaces, Foundation Models, fine-tuned LLMs, and other tools, we can start to see how this futuristic vision might become a reality…
And given the rapid rate of innovation, perhaps it will happen even sooner than we think.
Data Architecture Advice
Looking to modernize your data architecture or get help implementing Databricks or Snowflake? The team at Data Clymer can help. Check out our data architecture consulting services or contact us for a free consultation.

